GOBLIN DBpedia for ‘smaller’ languages
(A Network of Excellance project ~10kkr / year)
Open Knowledge has enjoyed a significant increase in popularity and usage in the last decade. Vast amounts of open and integrated knowledge have been published and made available for exploitation by the academy and industry. This knowledge has been primarily nurtured and generated by the Linked Open Data (LOD) initiative, which has attracted communities from many domains, such as life sciences, government, geography and linguistics. Datasets from the LOD cloud are used as a knowledge source in many general artificial intelligence applications, including question answering systems, such as IBM Watson that beat human champions in the Jeopardy knowledge quiz in 2011 (Ferucci et al, 2012), or major search engines. In 2018, the international consultancy firm Gartner has identified Knowledge Graphs as a key technology for Artificial Intelligence (Gartner, 2018).
Large commercial companies, such as global Internet search vendors, rely increasingly on proprietary knowledge graphs. While these are algorithmically distilled typically from Wikipedia and other open knowledge sources and integrated with proprietary sources, they are not freely available to competition and their transparency is very limited. It is vital that companies as well as researchers retain access to open knowledge graphs as public good. These need to have competitive quality and scope to those used internally by global IT hegemons. Possibly even more important is the maintenance of a transparent, community-driven processes determining which information enters the knowledge graph and how it is processed. Only in this way can the public retain accountability and control of knowledge-based algorithmic decision making and prevent algorithmic biases and discrimination.
Since 2007, when the LOD cloud was started with only 14 datasets, the number of published datasets has increased exponentially. From 45 datasets in 2008, 295 in 2011, and 570 in 2014, to 1,229 published datasets in June 2018 (LOD stats). Within the LOD cloud, the “links” are the key enabler for retrieval of related information from different datasets. They are also one of the key prerequisites for a dataset to be included as part of the LOD network of datasets. Over the years, DBpedia has become one of the most widely used datasets and one of the central interlinking hubs in the LOD cloud. The ultimate goal of the DBpedia project is to build a large-scale, multilingual knowledge graph by providing structured information extracted from Wikipedia. Over the last ten years, DBpedia has grown into a large community with 22 language chapters established in several European and overseas countries. Over the years, the user community around DBpedia has significantly grown. According to the bibliographic database Google Scholar, there are 28,300 articles citing DBpedia; using DBpedia or developing technology for DBpedia. In parallel to DBpedia, there are also several complementary knowledge graphs, such as Wikidata, YAGO, BabelNet and DBkWik. YAGO is a semantic knowledge graph, derived from Wikipedia and complemented with information from WordNet and GeoNames. YAGO (Rebele et al, 2016) provides a comprehensive entity classification schema which has been developed based on the Wikipedia article category information. Wikidata (Ismayilov et al, 2018) is a collaboratively created knowledge graph supported and hosted by the Wikimedia Foundation. Wikidata is highly focused on “centralization” of the information for different Wikimedia projects, i.e. i) centralization of interlanguage links in Wikipedia and ii) central access to data in a similar fashion as Wikimedia Commons for multimedia content. BabelNet (Ehrmann et al, 2014) is another knowledge development initiative which creates and maintains a multilingual knowledge resource containing concepts and named entities lexicalized in different languages. This knowledge graph is primarily based on information derived from Wikipedia and Wordnet, but also Wiktionary, GeoNames and Wikidata. DBkWik (Hofmann et al, 2017) is a recently created knowledge graph, which consolidates knowledge extracted from thousands of Wikis. DBkWik extracts knowledge from Wikis available in Wikia, which is one of the most popular Wiki farms. In addition to these open or semi-open initiatives, there are proprietary knowledge graphs (Pauheim, 2017), such as Google’s Knowledge Vault, Microsoft’s Satori or Facebook’s Entities graph.
There are several aspects which make the presented COST Action proposal focus primarily on DBpedia rather than on any of the previously mentioned knowledge graphs.
i) DBpedia is a decentralized, community-driven effort. Individual languages in DBpedia are maintained by national DBpedia language chapters. These in many cases unite several institutions. In comparison, the efforts behind most other knowledge graphs are centralized and usually driven by a single institution.
ii) Unique to DBpedia are its communities centralized around individual languages. These have different and complementary research focuses, such as linguistics, knowledge extraction, knowledge engineering and ontologies, Web technologies, scalable systems, data mining, information retrieval and data quality. The entire DBpedia ecosystem, and the DBpedia knowledge graph in particular, can benefit from the diverse expertise of the members behind each DBpedia language chapter. Also, different language chapters have different domains in their focus making DBpedia as a whole improve in its horizontal perspectives (research), but also in vertical perspectives (domains). Over the years, the community around DBpedia has significantly grown.
iii) DBpedia is highly integrated (i.e. interlinked) within other resources in the LOD cloud, such as YAGO, Wikidata, BabelNet and DBkWiki. These provide rich and comprehensive information, which is linked and integrated with the DBpedia knowledge graph. DBpedia, as a consequence, acts as a data access proxy to these and many other knowledge sources. It enables efficient and effortless retrieval and integration of knowledge from multiple sources. In short, DBpedia provides Global and Unified Access to Open Knowledge.
SoftAI, EU FET, June 3rd 2020, resubmitted May 2020
The “Human in the Loop – Soft AI for the Future of Work” -project explores human-centric AI in a highly transdisciplinary manner targeting to develop new methodology for “Soft AI” development based on citizen engagement and art as an intermediary between human and technology. Based in the fundamental rights in respect for human dignity, including those set out in the Treaties of the European Union and Charter of Fundamental Rights of the European Union, the project group consisting of AI developers, cognitive scientists, philosophers, designers, innovation managers, artists, and SMEs of different fields strives to ensure that human values are central to the way in which AI systems are developed, deployed, used and monitored by developing new ideology, research methodology, and technology in order to support and enhance human values, beliefs and goals in their connection to AI. The project focus is on developing new methods for augmenting human thinking, learning, creativity, empathy, connection, equality, and well-being in the context of the future of work where we see most European citizens will be affected most by the development of AI and automation.
AVRUS – Protecting Vulnerable Road Users (RISE, KTH, VTI) (Rebuilding consortium, Kapsch, Bosch eBikes, Ericsson)
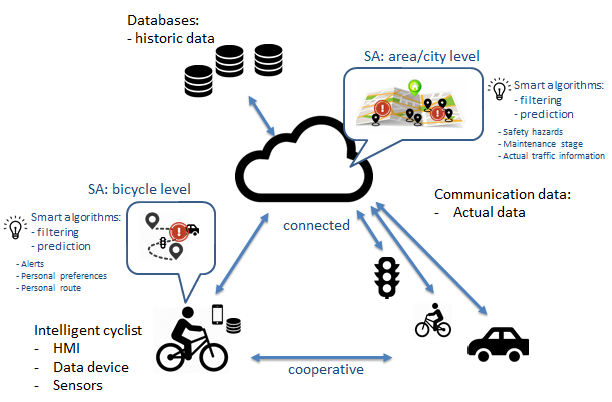
A systematic view for safer roads.
The project will make traffic safer for all road users. Whilst much attention is given to vehicle traffic safety, other road users such as pedestrians, cyclists, E-scooters and even wheelchair users still remain exposed. Standard transport methods are becoming more autonomous to avoid dangers, but vulnerable users cannot easily be computer-controlled for safety. This project uses augmented awareness to avoid common road risks for vulnerable people. In conjunction with other VRUs, the infrastructure and road monitoring infrastructure communicates directly, or via the cloud, against collision avoidance. The beneficiaries are i) vulnerable road users ii) society, which carries much of the cost for rehabilitation after accidents iii) insurance companies who cover the healthcare costs and loss of income iv) new infrastructure businesses v) phone app marketplace. The anonymized data from VRUs and road traffic conditions has potential for both public and commercial entities.
Interlunium – Bringing AI to Data (RISE, Logical Clocks (SE), Almende (NL), SZATAKI (HU))

Figure 1: Interlunium augments existing cloud and container systems enabling data processing collaborative, safe and productive, and through sharing, cheaper.
A number of studies have shown that Europe is losing the race in terms of AI and data, with the United States and China going neck-and-neck, despite having more researchers within AI [AIRACE, DataMarket]. One frequently cited reason for this is that many owners of large datasets are reluctant to share this information across country borders due to legal constraints or privacy concerns, which limits the scale at which analysis can take place. Since AI needs a certain critical mass of data to learn and become useful, this severely limits the number of successful AI applications or partners short of a technical solution.
On the other hand, public bodies such as the European Commission (EC) and the Big Data Value Association (BDVA) have stressed the importance of human-centric AI. They respect the rights of the individual as potential areas where European companies can still make headway, and it has made this a key topic in the European strategy around artificial intelligence and data.
Interlunium aims to be the solution which combines the factors of human-centric AI [EU-AI]. This is the cornerstone of European AI strategy with the inherent economies of scale which can be achieved by leveraging and sharing data. This is a current competitive advantage between US and Chinese markets which encourages trust in AI, necessary for large traditional European companies.
- Deploying software, data and AI with geographic, rights or policy restrictions
- Interpreting local rules: conditions, contracts
- Hassle-free operations as close to devops-free as possible
RESES – Predictive Maintenance (430 kkr)
The aim is to improve monitoring on industrial machines by better time-series/signal processing for existing Swedish solutions. Reses’s approach is to use a Bayesian time-series based ML technique (CausalImpact) for predicting machine issues and failures. RISE and Relianeering AB will contribute to PiiA’s mission by bringing in modern data-driven techniques to existing practices with process automation, towards an Industry 4.0 vision.
For the final project (this is a prestudy), the performance goal will be a marked improvement in the detection of failing machines. Since Relianeering is company monitoring in-situ machines, we can see if RISE’s Bayesian time series approach satisfies Relianeerings’ and their customer performance goals. An early indicator of the potential can be done with historical data, as already being collated via Relianeerings ReSES CM Cloud service. From other studies, we would expect at least 10% better prediction, which with 500 deployed units, this is a significant saving for customers.
A goal specified by customers of Relianeering, is a ‘quick check’ approach. That is, “something is wrong, is it normal/abnormal” and investigate it via existing data. Some call this “human in the loop” in AI, in this case we want to have “data in the loop” of predictive maintenance. The prestudy will indicate in much more detail, and examples, how this is done with operational deployed installations.
ClearFlow
The societal challenge we address is poor quality air conditions in Swedish cities. Pollutants from carbon-based fuel engines are detrimental to all urban lives creating an environmental challenge for the next decades. Children are particularly at risk, as brain development is inhibited by sub-micron particles. Timely, new bypass routes are being built in northern Stockholm, and we will capture the effect of these new roads within the 2 years of ClearFlow. The news value of the problem is “does road traffic contribute to poor air quality in Stockholm, if so, when, where and to what degree?”.
The market conditions are rife for a public-leaning air quality measurement platform & deployment. Although there are projects and sensors, there is no cheap, open-sourced, cellular-ready platform dedicated to measuring air quality. The energy saving potential is significant, as we use small single board sensors. They can run on an external 5V source, a la mobile power packs, or even solar power. The processing platform in Luleå, housed in an energy efficient environment, with energy saving measures, i.e. using the local temperatures.
The environmental relevance is that pollutants from heavily used transport paths, not least the roads in Stockholm. Internet-driven deliveries of packets are delivered in diesel-powered vehicles. Second, winter studded tyres contribute to air particulates. Third particulates also come from factories in eastern europe. Background 2.5/5/10 PM values need to be known to eliminate their effect. ClearFlow delivers a Swedish system using the Urban ICT arena to measure pollutants and correlate to local traffic. The solution can be deployed in any city, but ClearFlow focuses on the environmental impact on Stockholm due to the nearby E4. It will deliver an open-source operating system, platform, data. We will dissemination knowledge and lessons using experts in road traffic, communications, measurements and data processing
Clearflow – Correlating air quality monitoring with traffic flow.
Figure 1: ClearFlow fuses sensor and public data for value to city residents